前回までで、カメラで撮影した画像から、数独盤面の画像を切り出すことができた。次のステップはその盤面の画像の各マスの文字を認識し、問題をコンピュータで処理できる数学的表現に置き換えることである。そこで、盤面の画像をOCRを使って二次元のリストに変換することを考える。
Tesseract OCRは、HPが開発していたOCRエンジンをGoogleが引き継いでオープンソース化したC++用のOCRライブラリである。各言語用のラッパーが用意されているので、以前Java用のTess4Jというラッパーを利用した。
PythonからこのOCRエンジンを使うためのラッパーも用意されていて定評があるようだし、OCRのエンジンをPythonから利用できると今後広く応用できそうである。そこで、この機会にPythonからOCRエンジンを使えるような環境を作り、それを使って数独の文字認識を行うことにした。以下はそれに関しての備忘録である。
★Tesseractのインストール
Windows用のインストーラーは
https://github.com/UB-Mannheim/tesseract/wiki
にある。現在の最新版はv5.0.0のアルファのようだが、うまく動かなかったので、Older Versionから安定していると思われる tesseract-ocr-w64-setup-v4.1.0.20190314.exe をダウンロードした。 インストーラ―を実行の途中で、日本語を認識させるために、
Additional script data (download) で日本語関連ファイルを追加
Additional language data (download) で日本語関連ファイルを追加 するようになっている。
デフォールトでセットアップすると、Tesseractが
C:\Program Files\Tesseract-OCR 以下にインストールされる。
★日本語認識のテスト
インストールしたTesseract.exeの性能を適当な日本語の文章の画像を使ってテストしてみる。
入力する画像として本ブログについて書いている「本サイトについて」の文の一部を画像化して下図のようなFoolInTheValley.jpgというファイルを作った。

下に示すようにコマンドラインで、Teseract.exeを、入力ファイルにFoolInTheValley.jpg、出力ファイルにout_sample.txtを指定して実行してみる。
D:\Dev\Anaconda\Work>tesseract.exe FoolInTheValley.jpg out_sample -l jpn Tesseract Open Source OCR Engine v4.0.0.20190314 with Leptonica
文字認識結果のout_sample.txt というテキストファイルが生成され、
D:\Dev\Anaconda\Work>dir out_sample.txt ドライブ D のボリューム ラベルは Data です ボリューム シリアル番号は D2B6-509E です D:\Dev\Anaconda\Work のディレクトリ 2020/10/05 14:56 643 out_sample.txt 1 個のファイル 643 バイト 0 個のディレクトリ 500,870,369,280 バイトの空き領域
その内容は下のようになっている。
The Beatles の Magical Mystery Tour というアルバムに The Fool on the Hil
という曲があります。来る日も来る日も丘の上に一人でいて、陽が沈むおのを眺
め、世界が廻っているのを感じているという仙人のような人物をテーマにした
歌です。The Bealtes が一時期影響べされたインドのマハリシがモデルとも言わ
れていますが、 地動説を唱えた Galileo Galilei という説もちります。 もう 50 年
以上も前にリリースされた歌ですが、ごの曲の持つ独特な世界にはなにか惹か
れるものを感じます。
特別な前処理をせずに、入力ファイルを指定して実行するだけで、高い精度で日本語の文字認識ができているのは驚きである。
一文字の英数字の認識であれば、Tesseractを使えば訳もないことのようである。
★「PyOCR」
PythonプログラムからTesseractを利用するためには、「PyOCR」というラッパーを利用する。これはPython Package Indexにライブラリとして登録されていて、
python -m pip install pyocr
でインストールできる。このとき、画像処理ライブラリPillow(PIL)も一緒にインストールされる。
PythonでPyOCRを実行するには
- pyocr.get_available_tools()関数で使用可能なOCRエンジンを取得する
- PILからインポートしたImageのopen()関数で画像ファイルを読み込む
- image_to_string()関数で画像、言語、builderとして文字認識用のTextBuilder()を指定して認識を実行する。
で行うようになっており、具体的には次のようなコードを実行すればよい。
from PIL import Image # Python Image Library import pyocr import pyocr.builders tools = pyocr.get_available_tools() tool = tools[0] im = Image.open("./c7_10.jpg") txt = tool.image_to_string(im, lang="eng", builder = pyocr.builders.TextBuilder(tesseract_layout=10) )
ここでは、数字の認識だけなので言語をengとしている。また、tesseract_layoutは認識のモードを規定するもので、画像を一文字として認識させるためのモードである10を指定している。
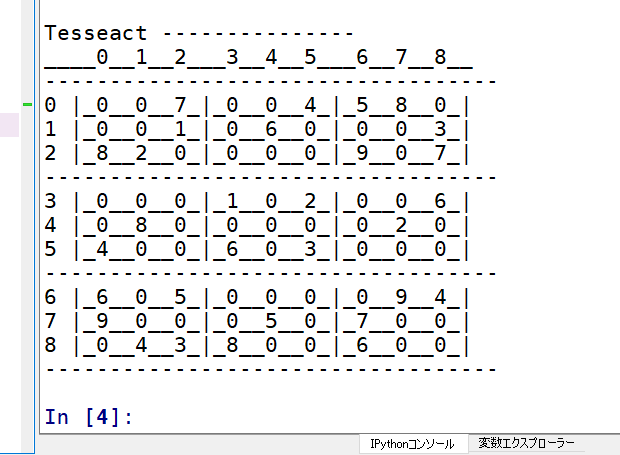
下の画像は、前回、数独の問題を任意の角度から撮影した写真に画像処理を施し、正対した白黒の盤面図に変形したものである。

これから各マスを切り出して下に示すような81個のファイルを作る。

これらの81個のファイルに対して、上述したpyocrを実行した結果を下に示す。便宜上、ブランクの場所を0としている。前出の画像と比較すると、問題を抽出できて、正しい二次元リストが得られていることがわかる。
以上で問題をコンピュータで処理できる数学的表現に置き換えることができたので、次はそれを解くことになる。
数独でPythonを 4 ← → 数独でPythonを 6
ーーーーーーーーーーーーーーーーー
